Object-Relational Language and modern tradeoffs in software
technology
Anton G. Kolonin
1997-2000
The presented Object-Relational Language (ORL) is approaching to solve few
tradeoffs existing in the modern computer technology.
Object-Oriented Business Logic vs. Relational Data Access. The modern
software is being developed in C++, Java and other object-oriented languages
while the data resides in relational databases accessible via SQL. To take
things together, various interfacing gateways such as JDBC, ODBC and so forth
are used to “glue” the alien parts.
ORL handles Objects and Relations in the sense that Objects are instances of
Relations (being used in relational algebra). Put it in other way, Classes in
ORL stands for Relations in relational algebra. Syntactically, ORL implements
the Smalltalk and Java style of accessing objects, their methods and data
members. At the same time, ORL incorporates SQL-alike queries as an optional
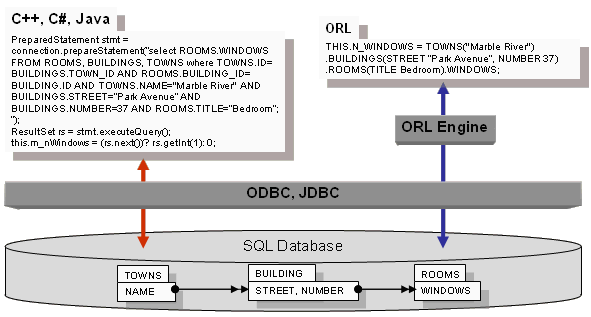
property of member access path. For example, if there is a need to get a number
of widows in the bedroom of the Park Avenue, 37 building in the town of Marble
River, it could be done with a following ORL statement.
N_WINDOWS = TOWN("Marble River").BUILDINGS
(STREET “Park Avenue”, NUMBER 37).ROOMS(TITLE Bedroom).WINDOWS;
The appropriate SQL statement would look like the following.
select ROOMS.WINDOWS FROM ROOMS, BUILDINGS, TOWNS where TOWN.ID=
BUILDINGS.TOWN_ID AND ROOMS.BUILDING_ID= BUILDING.ID AND TOWNS.NAME="Marble
River" AND BUILDINGS.STREET=“Park Avenue” AND BUILDINGS.NUMBER=37 AND
ROOMS.TITLE=”Bedroom”;
From the SQL database perspective, TOWN, BUILDING, ROOM are tables while
BUILDINGS, ROOMS and WINDOWS are either auxiliary linkage tables or just a way
to let some child relationship (e.g. ROOM) get linked to the parent relationship
(e.g. BUILDING) via primary and foreign keys. From the ORL engine perspective
TOWN, BUILDING and ROOM are classes while BUILDINGS, ROOMS and WINDOWS are
plural data members. Moreover, the ("Marble River") is a way to tell we are
selecting the object with NAME="Marble River" while (STREET “Park Avenue”,
NUMBER 37) specifies selection of the building where STREET=“Park Avenue” AND
NUMBER=37.
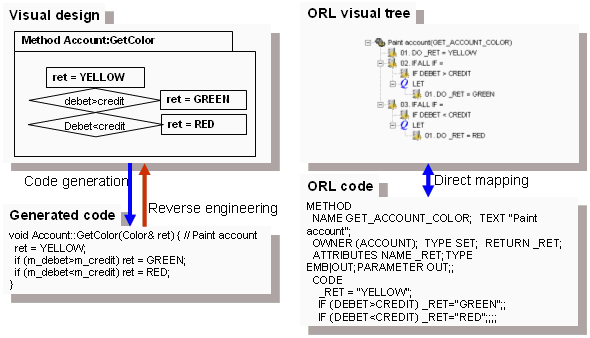
Visual Design vs. Textual Programming. The software of today is
designed with sophisticated visual modeling technologies starting with UML
diagrams and ending with wizards in C++ and Java IDEs. However, the real coding
is being carried out with source codes while 99% of the sources could hardly get
mapped to original diagrams since the real programming work is started.
The ORL comes with initially predefined classes needed to build declarative and
interrogative statements with unconditional and conditional operators, implicit
loops and method invocations. In turn, an ORL implementation provides a way to
render the ORL objects as trees or networked diagrams plus it supports reading
the ORL objects from the text stream and serializing them back to text. Then,
mapping from visual representation to source text and back happens
transparently.
From the ORL parser perspective, the only one real language statement is Query,
which is subclass of Method. What is going on during file input is just direct
translation of input file characters into query object and running such a query.
In its turn, query itself creates, modifies or even deletes objects in memory.
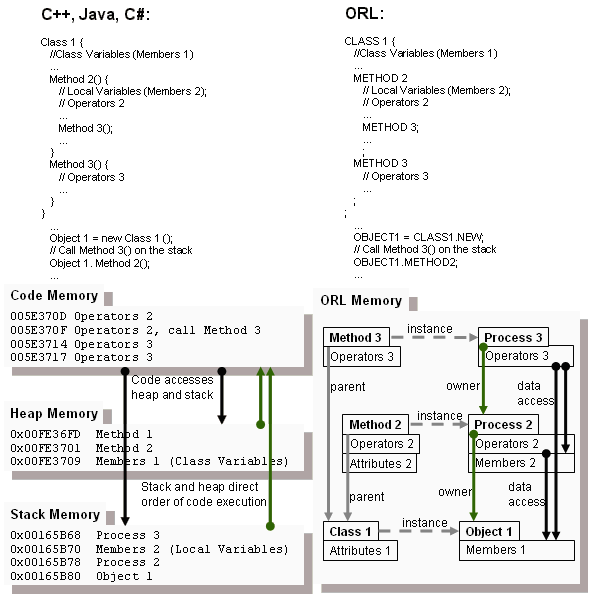
Object-Oriented Business Logic Definition vs. Procedural Business Logic
Execution. While most of the modern software logic is defined following the
object-oriented approach, so that application design comes as unity of classes
and objects, the execution is carried out in the old century manner, with
necessity to translate the sources to code or pseudo-code in form of
step-by-step instructions and then execute the pseudo code with an appropriate
sequential processor, maintaining the procedural calls on the stack.
The ORL semantics is identical to underlying engine semantics, including classes
representing statements and operators. That means, no any "compilation" is
needed to put source code into executable format or, in other words, source code
is equal to p-code. Run-time Process is just subclass of Object with members
serving as local variables. Function is subclass of Class with arguments as
constructor parameters. One difference between plain Object and Process is
lifecycle – Object is persistent while Process is transient – upon the function
call, the Process instance of Function class is created and it is destroyed upon
completion. Further, the Methods are just Functions bound to particular Class
and they transparently inherit members of the parent class, in expected way.
Interestingly enough, this gives a fancy yet easy way of live Process
serialization – the Process object instance could get suspended on one machine,
serialized into ORL text, sent to another machine and resumed right there.
Data Manipulation Language vs. Metadata Manipulation Language. When it
comes down to representing the data and content, there is always a need to deal
with structures keeping the data and then with content filling the structures.
While, in the real life, a data on itself may define a structure, modern
languages drive the sharp borderline between the metadata manipulation language
(SQL DDL, XML DTD) and data manipulation language (SQL DML, XML).
The ORL breaks the boundary between object and class. No any sort of Java
reflection or Microsoft-specific C++ compiler tricks are needed to create a new
class on runtime or detach and reattach an implementation method for a live
class or even object instance in the course of ORL program execution. ORL
explicitly asserts that the class is just regular object of class "class".
Indeed, ORL implementation engine starts from two objects. Those objects are
class "object" inherited by class "class" and class "class" with two
instantiated class objects ("object" and "class"). Moreover, ORL doesn't make
fundamental distinction between "class" (as abstract entity) and "object" (as
specific instance). This is because while one might think about object "Bob" as
instance of class "Man", another might think about "Angry Bob" and "Happy Bob"
as about specific instances of class "Bob".
Practically, the only things that could make offsprings of class “Class”
appearing differently from offsprings of class “Object” are custom security
policies and custom screens and methods defined for particular classes by given
ORL implementation, application or user.
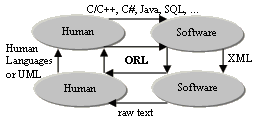
Parseability for Software-Software Interactions vs. Readability for
Human-Software Interactions. Currently, the languages in software technology
are specialized so that either texts in a language are manageable by human
(programming languages) or they are easily parsed with software. XML is declared
as a language not for a human reader and it really is. There is no convenient
way for user to intercept and make sense of software-to-software communication
and there is no standard way for human to get a message from software, amend it
and forward to software back.
ORL statements read from any stream (local file or remote URL) turn in ORL
objects in memory and might be easily saved back as ORL statements into another
stream – the parsing and dumping are transparent so no translation is needed to
let one engine communicate with another on the network.
The language is bi-directional – it defines not only the way for human or one
software system to pose an order or inquiry to another software system, it also
give a way to return results in the same syntax so they could be comprehended in
turn, in the same way. That is, the ORL dialogues between software and human
agents are completely symmetric. This is an invaluable feature for distributed
systems.
After all, the ORL syntax is more compact and readable than SQL and it is much
more readable and compact than XML so it can be employed by human agents to full
extent.
Structured Content Model vs. Semi-structured Representation Model.
From perspective of the Semantic Web movement, the future of the web appears as
a hyper-complex world-wide structure of cross-linked semantic relationships.
However, this is being implemented now with various extensions of XML (e.g. OWL
and RDF) developed originally to handle strictly hierarchical hypertext
structures.
It is explicit that ORL is intended to deal with structured data cross-linked in
an arbitrary manner. It is not a markup language where you put tags in the raw
text assuming the implementation will make sense of how the tags relate one to
another and find a way to render the tagged text. Rather, it is a programming
and query language where you can assign every variable a value – a text value
assuming there is an implementation method for using this variable or a
“reference” value specified as inline ORL query.
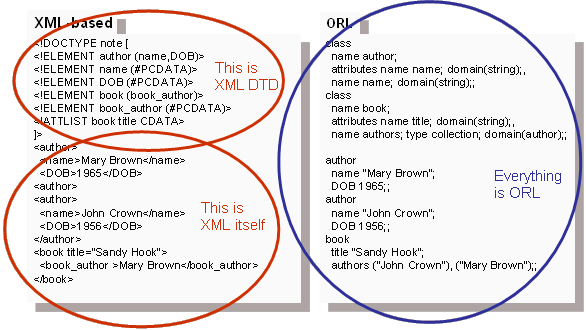
With XML, one may face an ambibuity how to declare a database of authors and
books – using XML attributes or tag content. There could be few variations of
the following encoding and there still would be a need to implement a custom way
to associate books with their authors.
<author><name>Mary Brown</name><DOB>1965</DOB><author>
<author><name>John Crown</name><DOB>1956</DOB><author>
<book title=”Sandy Hook”><book_author>John Crown</book_author><book_author >Mary
Brown</book_author></book>
ORL make this compact, certain and explicit in the following way. Note that the
authors of the book are referenced “by reference” using the ORL query statement.
author name “Mary Brown”; DOB 1965;;
author name “John Crown”; DOB 1956;;
book title ”Sandy Hook”; authors (“John Crown”), (”Mary Brown”);;
The major objection against ORL could be that it is not efficient to
represent a program in an ORL pseudo-code because it will be even more slow than
Java pseudo-code – this would bring the response time of a business application
down. However, in the most of modern business applications the performance
bottleneck resides within inter-module communications of distributed system and
unefficient design of data structures and queries (don’t consider applications
such as real-time face recognition from camera recordings for security
purposes). Moreover, it is quite possible and straightforward to generate C/C++
or Java code from ORL representation and then compile the code into binary
libraries on the fly (the only problem is that “hot replacement” of the binaries
is not currently supported by the OS, you would need a “cold restart” of the
system to have the changes reflected). After all, ORL implementation model
provides notion of “built-it” (i.e. “native”) classes or methods so that
response-time-critical code could be written in any convenient language.
There are few functions normally required for an ORL implementation.
Primarily, it is ability to save and read ORL objects using SQL databases, text
files, TCP/IP sockets and other data sources. Next, it is ability to execute
basic executable ORL objects such as instances of generic Process and Query, in
particular. Optional functions are GUI rendering of the ORL objects (for UI
applications) and distributed referential integrity control (for distributed
applications). So far, there are two existing “sample” implementations of the
ORL language, as follows.
First one is implementation of distributed application server and client
components for the back-office automation system built for
RTS Stock Exchange - the largest
Russian online stock trading company. The ORL kernel, client-side ORL GUI
rendering adapter and server-side ORL SQL database access adapter are written in
C/C++. The business logic and GUI screens are written in ORL entirely. System
can operate under Windows over TCP/IP.
Second one is distributed knowledge engineering platform called Webstructor
available on the web at
http://www.webstructor.net/. Peer-to-peer agent components and 3D graphics
interface based on ORL kernel are all written in pure Java using plain JDK. The
peer-to-peer components can operate under any OS over TCP/IP while client-only
components can operate under any browser over HTTP.
Having all that said, the question remains – if ORL is that good, should there
be something wrong? Yes, the wrong thing is that the language does not support
the Fuzzy Computing on itself. That is ORL can direct behavior to an application
or describe a data structure assuming the operation is either executed or not
and pieces of content are either associated or not. It can’t force an operation
to get executed with specified probability or assert a fuzzy relevance of one
piece of data to another. The latter is possible only with implementing
appropriate logic using the means of ORL itself or wait till appearance of Fuzzy
extension of ORL which is under development now.
More information on ORL is available on the web at
http://www.webstructor.net/docs/orl/.
History of ORL
1997-1999
Project
ProPro Group obtains the order from
RTS Stock Exchange to
develop Back-Office automation system
Requirements
Tremendous amount of initial business rules and forms
Possibility to amend and extend the business rules and forms
during the system life cycle
Problem
The RTS analysts are not capable to supply the representative
scope of initial business rules and forms timely enough so develoment can start
fitting the given time frame
Decision
ProPro gives RTS analysts a language to encode the business
rules and forms so the rules and forms can be quickly uploaded into the system
when done
ProPro develops a system which can upload business rules and
forms, play them in the course of system operation and provide an UI for the
amendment and extension of rules and forms on the fly.
Solution
Object-Relational Language (ORL) effectively usable by
analysts and software system at the same time
Universal Financial Object three-tier (client, middleware and
server) system using ORL for bootstrapping as well as intra-tier communications
(instead of DCOM).
1999-2000
Project
The idea came up to create a peer-to-peer internet-based tool
to share the mental models, impressions, charts and any “cool stuff” visually in
the virtual 3D space.
Requirements
Compact and parseable language used as protocol for two-way
data interchange between software agents.
High-level, and human readable language used to program and
debug the content presented visually.
Unify the above in the same language so the input-output
layers of the system are transparent and don’t care whether they talk to human
or computer agent.
Problems
XML is neither compact, not
human-readable
SQL is not symmetric so it can’t be
used for peer-to peer communications
Decision
Use the Object-Relational Language (ORL)
as successfully used before.
Solution
Webstructor - multi-agent
peer-to-peer graphics system for sharing the semantic models and 3D charts
around the virtual worlds spread around the the web-like cyberverse over the
internet (over HTTP or TCP/IP directly).